Цели, этапы и методы анализа временных рядов. Временные ряды, многомерные методы статистики и методы теории катастроф Пример анализа временных рядов
Введение
В данной главе рассматриваются задачи описания упорядоченных данных, полученных последовательно (во времени). Вообще говоря, упорядоченность может иметь место не только во времени, но и в пространстве, например, диаметр нити как функция её длины (одномерный случай), значение температуры воздуха как функция пространственных координат (трёхмерный случай).
В отличие от регрессионного анализа, где порядок строк в матрице наблюдений может быть произвольным, во временных рядах важна упорядоченность, а следовательно, интерес представляет взаимосвязь значений, относящихся к разным моментам времени.
Если значения ряда известны в отдельные моменты времени, то такой ряд называют дискретным , в отличие от непрерывного , значения которого известны в любой момент времени. Интервал между двумя последовательными моментами времени назовём тактом (шагом) . Здесь будут рассматриваться в основном дискретные временные ряды с фиксированной протяжённостью такта, принимаемой за единицу счёта. Заметим, что временные ряды экономических показателей, как правило, дискретны.
Значения ряда могут быть измеряемыми непосредственно (цена, доходность, температура), либо агрегированными (кумулятивными) , например, объём выпуска; расстояние, пройдённое грузоперевозчиками за временной такт.
Если значения ряда определяются детерминированной математической функцией, то ряд называют детерминированным . Если эти значения могут быть описаны лишь с привлечением вероятностных моделей, то временной ряд называют случайным .
Явление, протекающее во времени, называют процессом , поэтому можно говорить о детерминированном или случайном процессах. В последнем случае используют часто термин “стохастический процесс” . Анализируемый отрезок временного ряда может рассматриваться как частная реализация (выборка) изучаемого стохастического процесса, генерируемого скрытым вероятностным механизмом.
Временные ряды возникают во многих предметных областях и имеют различную природу. Для их изучения предложены различные методы, что делает теорию временных рядов весьма разветвленной дисциплиной. Так, в зависимости от вида временных рядов можно выделить такие разделы теории анализа временных рядов:
– стационарные случайные процессы, описывающие последовательности случайных величин, вероятностные свойства которых не изменяются во времени. Подобные процессы широко распространены в радиотехнике, метереологии, сейсмологии и т. д.
– диффузионные процессы, имеющие место при взаимопроникновении жидкостей и газов.
– точечные процессы, описывающие последовательности событий, таких как поступление заявок на обслуживание, стихийных и техногенных катастроф. Подобные процессы изучаются в теории массового обслуживания.
Мы ограничимся рассмотрением прикладных аспектов анализа временных рядов, которые полезны при решении практических задач в экономике, финансах. Основной упор будет сделан на методы подбора математической модели для описания временного ряда и прогнозирования его поведения.
1.Цели, методы и этапы анализа временных рядов
Практическое изучение временного ряда предполагает выявление свойств ряда и получение выводов о вероятностном механизме, порождающем этот ряд. Основные цели при изучении временного ряда следующие:
– описание характерных особенностей ряда в сжатой форме;
– построение модели временного ряда;
– предсказание будущих значений на основе прошлых наблюдений;
– управление процессом, порождающим временной ряд, путем выборки сигналов, предупреждающих о грядущих неблагоприятных событиях.
Достижение поставленных целей возможно далеко не всегда как из-за недостатка исходных данных (недостаточная длительность наблюдения), так из-за изменчивости со временем статистической структуры ряда.
Перечисленные цели диктуют в значительной мере, последовательность этапов анализа временных рядов:
1) графическое представление и описание поведения ряда;
2) выделение и исключение закономерных, неслучайных составляющих ряда, зависящих от времени;
3) исследование случайной составляющей временного ряда, оставшейся после удаления закономерной составляющей;
4) построение (подбор) математической модели для описания случайной составляющей и проверка ее адекватности;
5) прогнозирование будущих значений ряда.
При анализе временных рядов используются различные методы, наиболее распространенными из которых являются:
1) корреляционный анализ, используемый для выявления характерных особенностей ряда (периодичностей, тенденций и т. д.);
2) спектральный анализ, позволяющий находить периодические составляющие временного ряда;
3) методы сглаживания и фильтрации, предназначенные для преобразования временных рядов с целью удаления высокочастотных и сезонных колебаний;
5) методы прогнозирования.
2.Структурные компоненты временного ряда
Как уже отмечалось, в модели временного ряда принято выделять две основные составляющие: детерминированную и случайную (рис.). Под детерминированной составляющей временного ряда
понимают числовую последовательность , элементы которой вычисляются по определенному правилу как функция времени t . Исключив детерминированную составляющую из данных, мы получим колеблющийся вокруг нуля ряд, который может в одном предельном случае представлять чисто случайные скачки, а в другом – плавное колебательное движение. В большинстве случаев будет нечто среднее: некоторая иррегулярность и определенный систематический эффект, обусловленный зависимостью последовательных членов ряда.В свою очередь, детерминированная составляющая может содержать следующие структурные компоненты:
1) тренд g, представляющий собой плавное изменение процесса во времени и обусловленный действием долговременных факторов. В качестве примера таких факторов в экономике можно назвать: а) изменение демографических характеристик популяции (численности, возрастной структуры); б) технологическое и экономическое развитие; в) рост потребления.
2) сезонный эффект s , связанный с наличием факторов, действующих циклически с заранее известной периодичностью. Ряд в этом случае имеет иерархическую шкалу времени (например, внутри года есть сезоны, связанные с временами года, кварталы, месяцы) и в одноименных точках ряда имеют место сходные эффекты.
Рис. Структурные компоненты временного ряда.
Типичные примеры сезонного эффекта: изменение загруженности автотрассы в течение суток, по дням недели, временам года, пик продаж товаров для школьников в конце августа - начале сентября. Сезонная компонента со временем может меняться, либо носить плавающий характер. Так на графике объема перевозок авиалайнерами (см рис.) видно, что локальные пики, приходящиеся на праздник Пасхи «плавают» из-за изменчивости ее сроков.
Циклическая компонента c , описывающая длительные периоды относительного подъема и спада и состоящая из циклов переменной длительности и амплитуды. Подобная компонента весьма характерна для рядов макроэкономических показателей. Циклические изменения обусловлены здесь взаимодействием спроса и предложения, а также наложением таких факторов, как истощение ресурсов, погодные условия, изменения в налоговой политике и т. п. Отметим, что циклическую компоненту крайне трудно идентифицировать формальными методами, исходя только из данных изучаемого ряда.
«Взрывная» компонента i , иначе интервенция, под которой понимают существенное кратковременное воздействие на временной ряд. Примером интервенции могут служить события «черного вторника» 1994г., когда курс доллара за день вырос на несколько десятков процентов.
Случайная составляющая ряда отражает воздействие многочисленных факторов случайного характера и может иметь разнообразную структуру, начиная от простейшей в виде «белого шума» до весьма сложных, описываемых моделями авторегрессии-скользящего среднего (подробнее дальше).
После выделения структурных компонент необходимо специфицировать форму их вхождения во временной ряд. На верхнем уровне представления с выделением лишь детерминированной и случайной составляющих обычно используют аддитивную либо мультипликативную модели.
Аддитивная модель имеет вид
;мультипликативная –
Виды и методы анализа временных рядов
Временной ряд представляет собой совокупность последовательных измерений переменной, проведенных через одинаковые интервалы времени . Анализ временных рядов позволяет решать следующие задачи:
- исследовать структуру временного ряда, включающую, как правило, тренд - закономерные изменения среднего уровня, а также случайные периодические колебания;
- исследовать причинно-следственные взаимосвязи между процессами, определяющие изменения рядов, которые проявляются в корреляционных связях между временными рядами;
- построить математическую модель процесса, представленного временным рядом;
- преобразовать временной ряд средствами сглаживания и фильтрации;
- прогнозировать будущее развития процесса.
Значительная часть известных методов предназначена для анализа стационарных процессов, статистические свойства которых, характеризуемые при нормальном распределении средним значением и дисперсией, постоянны, не меняются с течением времени.
Но ряды часто имеют нестационарный характер. Нестационарность можно устранить следующим образом:
- вычесть тренд, т.е. изменения среднего значения, представленного некоторой детерминированной функцией, которую можно подобрать путем регрессионного анализа;
- выполнить фильтрацию специальным нестационарным фильтром.
Для стандартизации временных рядов в целях единообразия методов
анализа целесообразно провести их общее или посезонное центрирование путем деления на среднюю величину, а так же нормирование путем деления на стандартное отклонение.
Центрирование ряда удаляет ненулевое среднее значение, которое может затруднить интерпретацию результатов, например, при спектральном анализе. Цель нормирования - избежать в вычислениях операций с большими числами, что может привести к снижению точности расчетов.
После указанных предварительных преобразований временного ряда может быть построена его математическая модель, по которой осуществлено прогнозирование, т.е. получено некоторое продолжение временного ряда.
Чтобы результат прогноза можно было сопоставить с исходными данными, над ним следует произвести преобразования, обратные выполненным.
На практике наиболее часто используют методы моделирования и прогнозирования, а корреляционный и спектральный анализ рассматривают как вспомогательные методы. Это заблуждение. Методы прогнозирования развития средних тенденций позволяют получить оценки с существенными погрешностями, что весьма затрудняет прогнозирование будущих значений переменной, представленной временным рядом.
Методы корреляционного и спектрального анализа позволяют выявить различные, в том числе инерционные свойства системы, в которой идет развитие изучаемых процессов. Применение этих методов позволяет по текущей динамике процессов с достаточной уверенностью установить, как и с какой задержкой, известная динамика скажется на будущем развитии процессов. Для долгосрочного прогнозирования эти виды анализа позволяют получить ценные результаты.
Анализ и прогнозирование тренда
Анализ тренда предназначен для исследования изменений среднего значения временного ряда с построением математической модели тренда и с прогнозированием на этой основе будущих значений ряда. Анализ тренда выполняют путем построения моделей простой линейной или нелинейной регрессии.
Используемые исходные данные представляют собой две переменные, одна из которых - значения временного параметра, а другая - собственно значения временного ряда. В процессе анализа можно:
- опробовать несколько математических моделей тренда и выбрать ту, которая с большей точностью описывает динамику изменения ряда;
- построить прогноз будущего поведения временного ряда на основании выбранной модели тренда с определенной доверительной вероятностью;
- удалить тренд из временного ряда в целях обеспечения его стационарности, необходимой для корреляционного и спектрального анализа, для этого после расчета регрессионной модели необходимо сохранить остатки для выполнения анализа.
В качестве моделей трендов используют различные функции и сочетания, а так же степенные ряды, иногда называемые полиномиальными моделями. Наибольшую точность обеспечивают модели в виде рядов Фурье, однако не многие статистические пакеты позволяют использовать такие модели.
Проиллюстрируем получение модели тренда ряда. Используем ряд данных о валовом национальном продукте США на период 1929-1978 гг. в текущих ценах. Построим полиномиальную регрессионную модель. Точность модели повышалась, пока степень полинома не достигла пятой:
У = 145,6 - 35,67* + 4,59* 2 - 0,189* 3 + 0,00353х 4 + 0,000024* 5 ,
(14,9) (5,73) (0,68) (0,033) (0,00072) (0,0000056)
где У - ВНП, млрд дол.;
* - годы, отсчитываемые от первого 1929 г.;
под коэффициентами указаны их стандартные ошибки.
Стандартные ошибки коэффициентов модели малы, не достигают величин, равных половине значений коэффициентов модели. Это свидетельствует о хорошем качестве модели.
Коэффициент детерминации модели, равный квадрату приведенного коэффициента множественной корреляции составил 99%. Это означает, что модель объясняет данные на 99%. Стандартная ошибка модели оказалась равна 14,7 млрд, а уровень значимости нулевой гипотезы - гипотезы об отсутствии связи - менее 0,1%.
С помощью полученной модели можно дать прогноз, который в сопоставлении с фактическими данными приведен в табл. ПЗ. 1.
Прогноз и фактический размер ВНП США, млрд дол.
Таблица ПЗ.1
Прогноз, полученный с помощью полиномиальной модели, не слишком точен, о чем свидетельствуют данные, приведенные в таблице.
Корреляционный анализ
Корреляционный анализ необходим для выявления корреляций и их лагов - задержек их периодичности. Связь в одном процессе получила название автокорреляции, а связь между двумя процессами, характеризуемыми рядами - кросскорреляции. Высокий уровень корреляции может служить индикатором причинно-следственных связей, взаимодействий внутри одного процесса, между двумя процессами, а величина лага указывает временную задержку в передаче взаимодействия.
Обычно в процессе расчета значений корреляционной функции на к -м шаге вычисляется корреляция между переменными по длине отрезка / = 1,..., (п - к) первого ряда X и отрезка / = к ,..., п второго ряда К Длина отрезков, таким образом, меняется.
В результате получается некоторая трудная для практической интерпретации величина, напоминающая параметрический коэффициент корреляции, но не идентичная ему. Поэтому возможности корреляционного анализа, методику которого используют во многих статистических пакетах, ограничены узким кругом классов временных рядов, которые нехарактерны для большинства экономических процессов.
Экономистов в корреляционном анализе интересует исследование лагов в передаче воздействия от одного процесса к другому или влияния начального возмущения на последующее развитие того же самого процесса. Для решения таких задач была предложена модификация известного метода, названная интервальной корреляцией ".
Кулаичев А.П. Методы и средства анализа данных в среде Vindows. - М.: Информатика и компьютеры, 2003.
Интервальная корреляционная функция представляет собой последовательность коэффициентов корреляции, вычисленных между фиксированным отрезком первого ряда заданного размера и положения и равными им по размеру отрезками второго ряда, выбранных с последовательными сдвигами от начала ряда.
В определение добавляется два новых параметра: длина сдвигаемого фрагмента ряда и его начальное положение, а также используется принятое в математической статистике определение коэффициента корреляции Пирсона. Благодаря этому вычисляемые значения становятся сравнимы между собой и просто интерпретируемы.
Обычно для выполнения анализа необходимо выбрать одну или соответственно две переменные для автокорреляционного или кросскорреляцион-ного анализа, а так же задать следующие параметры:
Размерность временного шага анализируемого ряда для согласования
результатов с реальной временной шкалой;
Длину сдвигаемого фрагмента первого ряда, в виде числа включаемых в
него элементов ряда;
Сдвиг этого фрагмента относительно начала ряда.
Разумеется, необходимо выбрать вариант интервальной корреляции или иной корреляционной функции.
Если для анализа выбрана одна переменная, то вычисляются значения автокорреляционной функции для последовательно увеличивающихся лагов. Автокорреляционная функция позволяет определить, в какой степени динамика изменения заданного фрагмента воспроизводится в сдвинутых во времени его же отрезках.
Если для анализа выбраны две переменные, то вычисляются значения кросскорреляционной функции для последовательно увеличивающихся лагов - сдвигов второй из выбранных переменных относительно первой. Кросскорреляционная функция позволяет определить, в какой степени изменения фрагмента первого ряда воспроизводятся в сдвинутых во времени фрагментах второго ряда.
Результаты анализа должны включать оценки критического значения коэффициента корреляции г 0 для гипотезы «г 0 = 0» на определенном уровне значимости. Это позволяет не принимать во внимание статистически незначимые коэффициенты корреляции. Необходимо получить значения корреляционной функции с указанием лагов. Весьма полезны и наглядны графики авто- или кросскорреляционных функций.
Проиллюстрируем применение кросскорреляционного анализа на примере. Оценим взаимосвязи темпов прироста ВНП США и СССР за 60 лет с 1930 по 1979 гг. Для получения характеристик долгосрочных тенденций сдвигаемый фрагмент ряда выбран длиной 25 лет. В результате были получены коэффициенты корреляции при разных лагах.
Единственный лаг, при котором корреляция оказывается значимой - 28 лет. Коэффициент корреляции при этом лаге составляет 0,67, тогда как пороговое, минимальное значение - 0,36. Оказывается, что цикличность долгосрочного развития экономики СССР с лагом величиной 28 лет была тесно связана с цикличностью долгосрочного развития экономики США.
Спектральный анализ
Общепринятый способ анализа структуры стационарных временных рядов - это использование дискретного преобразования Фурье для оценки спектральной плотности или спектра ряда. Этот метод можно применять:
- для получения описательных статистик одного временного ряда или описательных статистик зависимостей между двумя временными рядами;
- для выявления периодических и квазипериодических свойств рядов;
- для проверки адекватности моделей, построенных другими методами;
- для сжатого представления данных;
- для интерполяции динамики временных рядов.
Точность оценок спектрального анализа можно повысить за счет применения специальных методов - использования сглаживающих окон и методов усреднения.
Для анализа необходимо выбрать одну или две переменные, при этом должны быть заданы следующие параметры:
- размерность временного шага анализируемого ряда, необходимая для согласования результатов с реальной временной и частотной шкалами;
- длина к анализируемого отрезка временного ряда, в виде числа включаемых в него данных;
- сдвиг очередного отрезка ряда к 0 относительно предыдущего;
- тип временного окна сглаживания для подавления в спектре так называемого эффекта вытекания мощности ;
- тип усреднения частотных характеристик, вычисленных на последовательных отрезках временного ряда.
Результаты анализа включают спектрограммы - значения характеристик амплитудно-частотной спектра и значения фазочастотных характеристик. В случае кросс-спектрального анализа результаты - это также значения передаточной функции и функции когерентности спектра. Результаты анализа могут включать и данные периодограмм.
Амплитудно-частотная характеристика кросс-спектра, называемая также кросс-спектральной плотностью, представляет зависимость амплитуды взаимного спектра двух взаимосвязанных процессов от частоты. Такая характеристика наглядно показывает, на каких частотах наблюдается синхронные и соответствующие по величине изменения мощности в двух анализируемых временных рядах или где находятся области их максимальных совпадений и максимальных несовпадений.
Проиллюстрируем применение спектрально анализа на примере. Проанализируем волны экономической конъюнктуры в Европе в период начала индустриального развития. Для анализа используем не сглаженный временной ряд индексов цен на пшеницу, усредненных Бевериджем по данным 40 рынков Европы за 370 лет с 1500 по 1869 г. Получим спектры
ряда и отдельных его отрезков продолжительностью 100 лет через каждые 25 лет.
Спектральный анализ позволяет оценить мощность каждой гармоники спектра. Наиболее мощными оказываются волны с 50-летним периодом, которые, как известно, были открыты Н. Кондратьевым 1 и получили его имя. Анализ позволяет установить, что сформировались они не в конце XVII - начале XIX в., как полагают многие экономисты. Они сформировались с 1725 по 1775 г.
Построение моделей авторегрессии и проинтегрированного скользящего среднего (ARIMA) считаются полезными для описания и прогнозирования стационарных временных рядов и нестационарных рядов, обнаруживающих однородные колебания вокруг изменяющегося среднего значения.
Модели ARIMA представляют собой комбинации двух моделей: авторегрессии {AR) и скользящего среднего (moving average - МА).
Модели скользящего среднего (МА) представляют стационарный процесс в виде линейной комбинации последовательных значений так называемого «белого шума». Такие модели оказываются полезными как в качестве самостоятельных описаний стационарных процессов, так и в качестве дополнения к моделям авторегрессии для более детального описания шумовой составляющей.
Алгоритмы вычисления параметров модели МА очень чувствительны к неправильному выбору числа параметров для конкретного временного ряда, особенно в сторону их увеличения, что может выражаться в отсутствии сходимости вычислений. Рекомендуется не выбирать на начальных этапах анализа модель скользящего среднего с большим числом параметров.
Предварительное оценивание - первый этап анализа с использованием модели ARIMA. Процесс предварительного оценивания прекращается по принятию гипотезы об адекватности модели временному ряду или по исчерпанию допустимого числа параметров. В итоге результаты анализа включают:
- значения параметров авторегрессионой модели и модели скользящего среднего;
- для каждого шага прогнозирования указываются - среднее значение прогноза, стандартная ошибка прогноза, доверительный интервал прогноза для определенного уровня значимости;
- статистику оценки уровня значимости гипотезы не коррелированное™ остатков;
- графики временного ряда с указанием стандартной ошибки прогноза.
- Значительная часть материалов раздела ПЗ основана на положениях книг: Басовский Л.Е. Прогнозирование и планирование в условиях рынка. - М.: ИНФРА-М, 2008. Гилмор Р. Прикладная теория катастроф: В 2 кн. Кн. 1/ Пер. с англ. М.: Мир, 1984.
- Жан Батист Жозеф Фурье (Jean Baptiste Joseph Fourier ; 1768-1830) - французский математик и физик.
- Николай Дмитриевич Кондратьев (1892-1938) - русский и советский экономист.
Цель анализа временных рядов обычно заключается в построении математической модели ряда, с помощью которой можно объяснить его поведение и осуществить прогноз на определенный период времени. Анализ временных рядов включает следующие основные этапы.
Анализ временного ряда обычно начинается с построения и изучения его графика.
Если нестационарность временного ряда очевидна, то первым делом надо выделить и удалить нестационарную составляющую ряда. Процесс удаления тренда и других компонент ряда, приводящих к нарушению стационарности, может проходить в несколько этапов. На каждом из них рассматривается ряд остатков, полученный в результате вычитания из исходного ряда подобранной модели тренда, или результат разностных и других преобразований ряда. Кроме графиков, признаками нестационарности временного ряда могут служить не стремящаяся к нулю автокорреляционная функция (за исключением очень больших значений лагов).
Подбор модели для временного ряда. После того, как исходный процесс максимально приближен к стационарному, можно приступить к подбору различных моделей полученного процесса. Цель этого этапа – описание и учет в дальнейшем анализе корреляционной структуры рассматриваемого процесса. При этом на практике чаще всего используются параметрические модели авторегрессии-скользящего среднего (ARIMA-модели)
Модель может считаться подобранной, если остаточная компонента ряда является процессом типа «белого шума», когда остатки распределены по нормальному закону с выборочным средним равным 0. После подбора модели обычно выполняются:
оценка дисперсии остатков, которая в дальнейшем может быть использована для построения доверительных интервалов прогноза;
анализ остатков с целью проверки адекватности модели.
Прогнозирование и интерполяция . Последним этапом анализа временного ряда может быть прогнозирование его будущих (экстраполяция) или восстановление пропущенных (интерполяция) значений и указания точности этого прогноза на базе подобранной модели. Не всегда удается хорошо подобрать математическую модель для временного ряда. Неоднозначность подбора модели может наблюдаться как на этапе выделения детерминированной компоненты ряда, так и при выборе структуры ряда остатков. Поэтому исследователи довольно часто прибегают к методу нескольких прогнозов, сделанных с помощью разных моделей.
Методы анализа. При анализе временных рядов обычно используются следующие методы:
графические методы представления временных рядов и их сопутствующих числовых характеристик;
методы сведения к стационарным процессам: удаление тренда, модели скользящего среднего и авторегрессии;
методы исследования внутренних связей между элементами временных рядов.
3.5. Графические методы анализа временных рядов
Зачем нужны графические методы. В выборочных исследованиях простейшие числовые характеристики описательной статистики (среднее, медиана, дисперсия, стандартное отклонение) обычно дают достаточно информативное представление о выборке. Графические методы представления и анализа выборок при этом играют лишь вспомогательную роль, позволяя лучше понять локализацию и концентрацию данных, их закон распределения.
Роль графических методов при анализе временных рядов совершенно иная. Дело в том, что табличное представление временного ряда и описательные статистики чаще всего не позволяют понять характер процесса, в то время как по графику временного ряда можно сделать довольно много выводов. В дальнейшем они могут быть проверены и уточнены с помощью расчетов.
При анализе графиков можно достаточно уверенно определить:
наличие тренда и его характер;
наличие сезонных и циклических компонент;
степень плавности или прерывистости изменений последовательных значений ряда после устранения тренда. По этому показателю можно судить о характере и величине корреляции между соседними элементами ряда.
Построение и изучение графика. Построение графика временного ряда – совсем не такая простая задача, как это кажется на первый взгляд. Современный уровень анализа временных рядов предполагает использование той или иной компьютерной программы для построения их графиков и всего последующего анализа. Большинство статистических пакетов и электронных таблиц снабжено теми или иными методами настройки на оптимальное представление временного ряда, но даже при их использовании могут возникать различные проблемы, например:
из-за ограниченности разрешающей способности экранов компьютеров размеры выводимых графиков могут быть также ограничены;
при больших объемах анализируемых рядов точки на экране, изображающие наблюдения временного ряда, могут превратиться в сплошную черную полосу.
Для борьбы с этими затруднениями используются различные способы. Наличие в графической процедуре режима «лупы» или «увеличения» позволяет изобразить более крупно выбранную часть ряда, однако при этом становится трудно судить о характере поведения ряда на всем анализируемом интервале. Приходится распечатывать графики для отдельных частей ряда и состыковыватьих вместе, чтобы увидеть картину поведения ряда в целом. Иногда для улучшения воспроизведения длинных рядов используетсяпрореживание, то есть выбор и отображение на графике каждой второй, пятой, десятой и т.д. точки временного ряда. Эта процедура позволяет сохранить целостное представление ряда и полезна для обнаружения трендов. На практике полезно сочетание обеих процедур: разбиения ряда на части и прореживания, так как они позволяют определить особенности поведения временного ряда.
Еще одну проблему при воспроизведении графиков создают выбросы – наблюдения, в несколько раз превышающие по величине большинство остальных значений ряда. Их присутствие тоже приводит к неразличимости колебаний временного ряда, так как масштаб изображения программа автоматически подбирает так, чтобы все наблюдения поместились на экране. Выбор другого масштаба на оси ординат устраняет эту проблему, но резко отличающиеся наблюдения при этом остаются за границами экрана.
Вспомогательные графики. При анализе временных рядов часто используются вспомогательные графики для числовых характеристик ряда:
график выборочной автокорреляционной функции (коррелограммы) с доверительной зоной (трубкой) для нулевой автокорреляционной функции;
график выборочной частной автокорреляционной функции с доверительной зоной для нулевой частной автокорреляционной функции;
график периодограммы.
Первые дваиз этих графиков позволяют судить о связи (зависимости) соседних значений временного рада, они используются при подборе параметрических моделей авторегрессии и скользящего среднего. График периодограммы позволяет судить о наличии гармонических составляющих во временном ряде.
Анализ временных рядов позволяет изучить показатели во времени. Временной ряд – это числовые значения статистического показателя, расположенные в хронологическом порядке.
Подобные данные распространены в самых разных сферах человеческой деятельности: ежедневные цены акций, курсов валют, ежеквартальные, годовые объемы продаж, производства и т.д. Типичный временной ряд в метеорологии, например, ежемесячный объем осадков.
Временные ряды в Excel
Если фиксировать значения какого-то процесса через определенные промежутки времени, то получатся элементы временного ряда. Их изменчивость пытаются разделить на закономерную и случайную составляющие. Закономерные изменения членов ряда, как правило, предсказуемы.
Сделаем анализ временных рядов в Excel. Пример: торговая сеть анализирует данные о продажах товаров магазинами, находящимися в городах с населением менее 50 000 человек. Период – 2012-2015 гг. Задача – выявить основную тенденцию развития.
Внесем данные о реализации в таблицу Excel:
На вкладке «Данные» нажимаем кнопку «Анализ данных». Если она не видна, заходим в меню. «Параметры Excel» - «Надстройки». Внизу нажимаем «Перейти» к «Надстройкам Excel» и выбираем «Пакет анализа».
Подключение настройки «Анализ данных» детально описано .
Нужная кнопка появится на ленте.

Из предлагаемого списка инструментов для статистического анализа выбираем «Экспоненциальное сглаживание». Этот метод выравнивания подходит для нашего динамического ряда, значения которого сильно колеблются.

Заполняем диалоговое окно. Входной интервал – диапазон со значениями продаж. Фактор затухания – коэффициент экспоненциального сглаживания (по умолчанию – 0,3). Выходной интервал – ссылка на верхнюю левую ячейку выходного диапазона. Сюда программа поместит сглаженные уровни и размер определит самостоятельно. Ставим галочки «Вывод графика», «Стандартные погрешности».
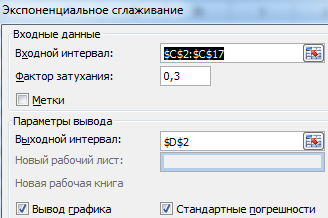
Закрываем диалоговое окно нажатием ОК. Результаты анализа:

Для расчета стандартных погрешностей Excel использует формулу: =КОРЕНЬ(СУММКВРАЗН(‘диапазон фактических значений’; ‘диапазон прогнозных значений’)/ ‘размер окна сглаживания’). Например, =КОРЕНЬ(СУММКВРАЗН(C3:C5;D3:D5)/3).
Прогнозирование временного ряда в Excel
Составим прогноз продаж, используя данные из предыдущего примера.
На график, отображающий фактические объемы реализации продукции, добавим линию тренда (правая кнопка по графику – «Добавить линию тренда»).
Настраиваем параметры линии тренда:
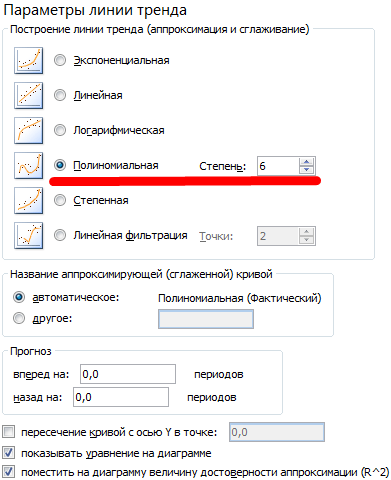
Выбираем полиномиальный тренд, что максимально сократить ошибку прогнозной модели.

R2 = 0,9567, что означает: данное отношение объясняет 95,67% изменений объемов продаж с течением времени.
Уравнение тренда – это модель формулы для расчета прогнозных значений.
Получаем достаточно оптимистичный результат:
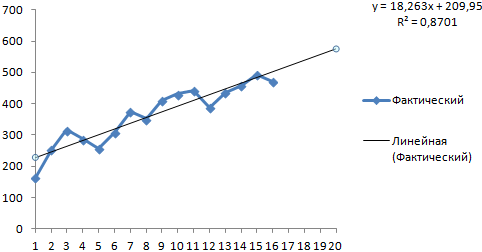
В нашем примере все-таки экспоненциальная зависимость. Поэтому при построении линейного тренда больше ошибок и неточностей.
Для прогнозирования экспоненциальной зависимости в Excel можно использовать также функцию РОСТ.

Для линейной зависимости – ТЕНДЕНЦИЯ.
При составлении прогнозов нельзя использовать какой-то один метод: велика вероятность больших отклонений и неточностей.
Отправить свою хорошую работу в базу знаний просто. Используйте форму, расположенную ниже
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Размещено на http://www.allbest.ru/
Федеральное агентство по образованию
Волгоградский государственный технический университет
КОНТРОЛЬНАЯ РАБОТА
по дисциплине: М одели и методы в экономике
на тему «Анализ временных рядов»
Выполнил: студентка группы ЭЗБ 291с Селиванова О. В.
Волгоград 2010г.
Введение
Классификация временных рядов
Методы анализа временных рядов
Заключение
Литература
Введение
Исследование динамики социально-экономических явлений, выявление и характеристика основных тенденций развития и моделей взаимосвязи дает основание для прогнозирования, то есть определения будущих размеров экономического явления.
Особенно актуальными становятся вопросы прогнозирования в условиях перехода на международные системы и методики учета и анализа социально-экономических явлений.
Важное место в системе учета занимают статистические методы. Применение и использование прогнозирования предполагает, что закономерность развития, действующая в прошлом, сохраняется и прогнозируемом будущем.
Таким образом, изучение методов анализа качества прогнозов является сегодня очень актуальным. Именно эта тема выбрана в качестве объекта исследования в данной работе.
Временной ряд -- это упорядоченная по времени последовательность значений некоторой произвольной переменной величины. Каждое отдельное значение данной переменной называется отсчётом временного ряда. Тем самым, временной ряд существенным образом отличается от простой выборки данных.
Классификация временных рядов
Временные ряды классифицируются по следующим признакам.
1. По форме представления уровней:
Ш ряды абсолютных показателей;
Ш относительных показателей;
Ш средних величин.
2. По характеру временного параметра:
Ш моментные. В моментных временных рядах уровни характеризуют значения показателя по состоянию на определенные моменты времени. В интервальных рядах уровни характеризуют значение показателя за определенные периоды времени.
Ш интервальные временные ряды. Важная особенность интервальных временных рядов абсолютных величин заключается в возможности суммирования их уровней.
3. По расстоянию между датами и интервалами времени:
Ш полные (равноотстоящие) - когда даты регистрации или окончания периодов следуют друг за другом с равными интервалами.
Ш неполные (не равноотстоящие) - когда принцип равных интервалов не соблюдается.
4. В зависимости от наличия основной тенденции:
Ш стационарные ряды - в которых среднее значение и дисперсия постоянны.
Ш нестационарные - содержащие основную тенденцию развития.
Методы анализа временных рядов
Временные ряды исследуются с различными целями. В одном ряде случаях бывает достаточно получить описание характерных особенностей ряда, а в другом ряде случаев требуется не только предсказывать будущие значения временного ряда, но и управлять его поведением. Метод анализа временного ряда определяется, с одной стороны, целями анализа, а с другой стороны, вероятностной природой формирования его значений.
Методы анализа временных рядов.
1. Спектральный анализ. Позволяет находить периодические составляющие временного ряда.
2. Корреляционный анализ. Позволяет находить существенные периодические зависимости и соответствующие им задержки (лаги) как внутри одного ряда (автокорреляция), так и между несколькими рядами. (кросскорреляция)
3. Сезонная модель Бокса-Дженкинса. Применяется когда временной ряд содержит явно выраженный линейный тренд и сезонные составляющие. Позволяет предсказывать будущие значения ряда. Модель была предложена в связи с анализом авиаперевозок.
4. Прогноз экспоненциально взвешенным скользящим средним. Простейшая модель прогнозирования временного ряда. Применима во многих случаях. В том числе, охватывает модель ценообразования на основе случайных блужданий.
Цель спектрального анализа - разложить ряд на функции синусов и косинусов различных частот, для определения тех, появление которых особенно существенно и значимо. Один из возможных способов сделать это - решить задачу линейной множественной регрессии, где зависимая переменная - наблюдаемый временной ряд, а независимые переменные или регрессоры: функции синусов всех возможных (дискретных) частот. Такая модель линейной множественной регрессии может быть записана как:
x t = a 0 + (для k = 1 до q)
Следующее общее понятие классического гармонического анализа в этом уравнении - (лямбда) -это круговая частота, выраженная в радианах в единицу времени, т.е. = 2** k , где - константа пи = 3.1416 и k = k/q. Здесь важно осознать, что вычислительная задача подгонки функций синусов и косинусов разных длин к данным может быть решена с помощью множественной линейной регрессии. Заметим, что коэффициенты a k при косинусах и коэффициенты b k при синусах - это коэффициенты регрессии, показывающие степень, с которой соответствующие функции коррелируют с данными. Всего существует q различных синусов и косинусов; интуитивно ясно, что число функций синусов и косинусов не может быть больше числа данных в ряде. Не вдаваясь в подробности, отметим, если n - количество данных, то будет n/2+1 функций косинусов и n/2-1 функций синусов. Другими словами, различных синусоидальных волн будет столько же, сколько данных, и вы сможете полностью воспроизвести ряд по основным функциям.
В итоге, спектральный анализ определяет корреляцию функций синусов и косинусов различной частоты с наблюдаемыми данными. Если найденная корреляция (коэффициент при определенном синусе или косинусе) велика, то можно заключить, что существует строгая периодичность на соответствующей частоте в данных.
Анализ распределенных лагов - это специальный метод оценки запаздывающей зависимости между рядами. Например, предположим, вы производите компьютерные программы и хотите установить зависимость между числом запросов, поступивших от покупателей, и числом реальных заказов. Вы могли бы записывать эти данные ежемесячно в течение года и затем рассмотреть зависимость между двумя переменными: число запросов и число заказов зависит от запросов, но зависит с запаздыванием. Однако очевидно, что запросы предшествуют заказам, поэтому можно ожидать, что число заказов. Иными словами, в зависимости между числом запросов и числом продаж имеется временной сдвиг (лаг) (см. также автокорреляции и кросскорреляции).
Такого рода зависимости с запаздыванием особенно часто возникают в эконометрике. Например, доход от инвестиций в новое оборудование отчетливо проявится не сразу, а только через определенное время. Более высокий доход изменяет выбор жилья людьми; однако эта зависимость, очевидно, тоже проявляется с запаздыванием.
Во всех этих случаях, имеется независимая или объясняющая переменная, которая воздействует на зависимые переменные с некоторым запаздыванием (лагом). Метод распределенных лагов позволяет исследовать такого рода зависимость.
Общая модель
Пусть y - зависимая переменная, a независимая или объясняющая x. Эти переменные измеряются несколько раз в течение определенного отрезка времени. В некоторых учебниках по эконометрике зависимая переменная называется также эндогенной переменной, a зависимая или объясняемая переменная экзогенной переменной. Простейший способ описать зависимость между этими двумя переменными дает следующее линейное уравнение:
В этом уравнении значение зависимой переменной в момент времени t является линейной функцией переменной x, измеренной в моменты t, t-1, t-2 и т.д. Таким образом, зависимая переменная представляет собой линейные функции x и x, сдвинутых на 1, 2, и т.д. временные периоды. Бета коэффициенты (i) могут рассматриваться как параметры наклона в этом уравнении. Будем рассматривать это уравнение как специальный случай уравнения линейной регрессии. Если коэффициент переменной с определенным запаздыванием (лагом) значим, то можно заключить, что переменная y предсказывается (или объясняется) с запаздыванием.
Процедуры оценки параметров и прогнозирования, описанные в разделе, предполагают, что математическая модель процесса известна. В реальных данных часто нет отчетливо выраженных регулярных составляющих. Отдельные наблюдения содержат значительную ошибку, тогда как вы хотите не только выделить регулярные компоненты, но также построить прогноз. Методология АРПСС, разработанная Боксом и Дженкинсом (1976), позволяет это сделать. Данный метод чрезвычайно популярен во многих приложениях, и практика подтвердила его мощность и гибкость (Hoff, 1983; Pankratz, 1983; Vandaele, 1983). Однако из-за мощности и гибкости, АРПСС - сложный метод. Его не так просто использовать, и требуется большая практика, чтобы овладеть им. Хотя часто он дает удовлетворительные результаты, они зависят от квалификации пользователя (Bails and Peppers, 1982). Следующие разделы познакомят вас с его основными идеями. Для интересующихся кратким, рассчитанным на применение, (нематематическим) введением в АРПСС, рекомендуем книгу McCleary, Meidinger, and Hay (1980).
Модель АРПСС
Общая модель, предложенная Боксом и Дженкинсом (1976) включает как параметры авторегрессии, так и параметры скользящего среднего. Именно, имеется три типа параметров модели: параметры авто регрессии (p), порядок разности (d), параметры скользящего среднего (q). В обозначениях Бокса и Дженкинса модель записывается как АРПСС (p, d, q). Например, модель (0, 1, 2) содержит 0 (нуль) параметров авто регрессии (p) и 2 параметра скользящего среднего (q), которые вычисляются для ряда после взятия разности с лагом 1.
Как отмечено ранее, для модели АРПСС необходимо, чтобы ряд был стационарным, это означает, что его среднее постоянно, а выборочные дисперсия и автокорреляция не меняются во времени. Поэтому обычно необходимо брать разности ряда до тех пор, пока он не станет стационарным (часто также применяют логарифмическое преобразование для стабилизации дисперсии). Число разностей, которые были взяты, чтобы достичь стационарности, определяются параметром d (см. предыдущий раздел). Для того чтобы определить необходимый порядок разности, нужно исследовать график ряда и автокоррелограмму. Сильные изменения уровня (сильные скачки вверх или вниз) обычно требуют взятия несезонной разности первого порядка (лаг=1). Сильные изменения наклона требуют взятия разности второго порядка. Сезонная составляющая требует взятия соответствующей сезонной разности (см. ниже). Если имеется медленное убывание выборочных коэффициентов автокорреляции в зависимости от лага, обычно берут разность первого порядка. Однако следует помнить, что для некоторых временных рядов нужно брать разности небольшого порядка или вовсе не брать их. Заметим, что чрезмерное количество взятых разностей приводит к менее стабильным оценкам коэффициентов.
На этом этапе (который обычно называют идентификацией порядка модели, см. ниже) вы также должны решить, как много параметров авто регрессии (p) и скользящего среднего (q) должно присутствовать в эффективной и экономной модели процесса. (Экономность модели означает, что в ней имеется наименьшее число параметров и наибольшее число степеней свободы среди всех моделей, которые подгоняются к данным). На практике очень редко бывает, что число параметров p или q больше 2 (см. ниже более полное обсуждение).
Следующий, после идентификации, шаг (Оценивание) состоит в оценивании параметров модели (для чего используются процедуры минимизации функции потерь, см. ниже; более подробная информация о процедурах минимизации дана в разделе Нелинейное оценивание). Полученные оценки параметров используются на последнем этапе (Прогноз) для того, чтобы вычислить новые значения ряда и построить доверительный интервал для прогноза. Процесс оценивания проводится по преобразованным данным (подвергнутым применению разностного оператора). До построения прогноза нужно выполнить обратную операцию (интегрировать данные). Таким образом, прогноз методологии будет сравниваться с соответствующими исходными данными. На интегрирование данных указывает буква П в общем названии модели (АРПСС = Авто регрессионное Проинтегрированное Скользящее Среднее).
Дополнительно модели АРПСС могут содержать константу, интерпретация которой зависит от подгоняемой модели. Именно, если (1) в модели нет параметров авто регрессии, то константа есть среднее значение ряда, если (2) параметры авто регрессии имеются, то константа представляет собой свободный член. Если бралась разность ряда, то константа представляет собой среднее или свободный член преобразованного ряда. Например, если бралась первая разность (разность первого порядка), а параметров авто регрессии в модели нет, то константа представляет собой среднее значение преобразованного ряда и, следовательно, коэффициент наклона линейного тренда исходного.
Экспоненциальное сглаживание - это очень популярный метод прогнозирования многих временных рядов. Исторически метод был независимо открыт Броуном и Холтом.
Простое экспоненциальное сглаживание
Простая и прагматически ясная модель временного ряда имеет следующий вид:
где b - константа и (эпсилон) - случайная ошибка. Константа b относительно стабильна на каждом временном интервале, но может также медленно изменяться со временем. Один из интуитивно ясных способов выделения b состоит в том, чтобы использовать сглаживание скользящим средним, в котором последним наблюдениям приписываются большие веса, чем предпоследним, предпоследним большие веса, чем пред предпоследним и т.д. Простое экспоненциальное именно так и устроено. Здесь более старым наблюдениям приписываются экспоненциально убывающие веса, при этом, в отличие от скользящего среднего, учитываются все предшествующие наблюдения ряда, а не те, что попали в определенное окно. Точная формула простого экспоненциального сглаживания имеет следующий вид:
S t = *X t + (1-)*S t-1
Когда эта формула применяется рекурсивно, то каждое новое сглаженное значение (которое является также прогнозом) вычисляется как взвешенное среднее текущего наблюдения и сглаженного ряда. Очевидно, результат сглаживания зависит от параметра (альфа). Если равно 1, то предыдущие наблюдения полностью игнорируются. Если равно 0, то игнорируются текущие наблюдения. Значения между 0, 1 дают промежуточные результаты.
Эмпирические исследования Makridakis и др. (1982; Makridakis, 1983) показали, что весьма часто простое экспоненциальное сглаживание дает достаточно точный прогноз.
Выбор лучшего значения параметра (альфа)
Gardner (1985) обсуждает различные теоретические и эмпирические аргументы в пользу выбора определенного параметра сглаживания. Очевидно, из формулы, приведенной выше, следует, что должно попадать в интервал между 0 (нулем) и 1 (хотя Brenner et al., 1968, для дальнейшего применения анализа АРПСС считают, что 0<<2). Gardner (1985) сообщает, что на практике обычно рекомендуется брать меньше.30. Однако в исследовании Makridakis et al., (1982), большее.30, часто дает лучший прогноз. После обзора литературы, Gardner (1985) приходит к выводу, что лучше оценивать оптимально по данным (см. ниже), чем просто "гадать" или использовать искусственные рекомендации.
Оценивание лучшего значения с помощью данных. На практике параметр сглаживания часто ищется с поиском на сетке. Возможные значения параметра разбиваются сеткой с определенным шагом. Например, рассматривается сетка значений от = 0.1 до = 0.9, с шагом 0.1. Затем выбирается, для которого сумма квадратов (или средних квадратов) остатков (наблюдаемые значения минус прогнозы на шаг вперед) является минимальной.
Индексы качества подгонки
Самый прямой способ оценки прогноза, полученного на основе определенного значения - построить график наблюдаемых значений и прогнозов на один шаг вперед. Этот график включает в себя также остатки (отложенные на правой оси Y). Из графика ясно видно, на каких участках прогноз лучше или хуже.
Такая визуальная проверка точности прогноза часто дает наилучшие результаты. Имеются также другие меры ошибки, которые можно использовать для определения оптимального параметра (см. Makridakis, Wheelwright, and McGee, 1983):
Средняя ошибка. Средняя ошибка (СО) вычисляется простым усреднением ошибок на каждом шаге. Очевидным недостатком этой меры является то, что положительные и отрицательные ошибки аннулируют друг друга, поэтому она не является хорошим индикатором качества прогноза.
Средняя абсолютная ошибка. Средняя абсолютная ошибка (САО) вычисляется как среднее абсолютных ошибок. Если она равна 0 (нулю), то имеем совершенную подгонку (прогноз). В сравнении со средней квадратической ошибкой, эта мера "не придает слишком большого значения" выбросам.
Сумма квадратов ошибок (SSE), среднеквадратическая ошибка. Эти величины вычисляются как сумма (или среднее) квадратов ошибок. Это наиболее часто используемые индексы качества подгонки.
Относительная ошибка (ОО). Во всех предыдущих мерах использовались действительные значения ошибок. Представляется естественным выразить индексы качества подгонки в терминах относительных ошибок. Например, при прогнозе месячных продаж, которые могут сильно флуктуировать (например, по сезонам) из месяца в месяц, вы можете быть вполне удовлетворены прогнозом, если он имеет точность?10%. Иными словами, при прогнозировании абсолютная ошибка может быть не так интересна как относительная. Чтобы учесть относительную ошибку, было предложено несколько различных индексов (см. Makridakis, Wheelwright, and McGee, 1983). В первом относительная ошибка вычисляется как:
ОО t = 100*(X t - F t)/X t
где X t - наблюдаемое значение в момент времени t, и F t - прогноз (сглаженное значение).
Средняя относительная ошибка (СОО). Это значение вычисляется как среднее относительных ошибок.
Средняя абсолютная относительная ошибка (САОО). Как и в случае с обычной средней ошибкой отрицательные и положительные относительные ошибки будут подавлять друг друга. Поэтому для оценки качества подгонки в целом (для всего ряда) лучше использовать среднюю абсолютную относительную ошибку. Часто эта мера более выразительная, чем среднеквадратическая ошибка. Например, знание того, что точность прогноза ±5%, полезно само по себе, в то время как значение 30.8 для средней квадратической ошибки не может быть так просто проинтерпретировано.
Автоматический поиск лучшего параметра. Для минимизации средней квадратической ошибки, средней абсолютной ошибки или средней абсолютной относительной ошибки используется квази-ньютоновская процедура (та же, что и в АРПСС). В большинстве случаев эта процедура более эффективна, чем обычный перебор на сетке (особенно, если параметров сглаживания несколько), и оптимальное значение можно быстро найти.
Первое сглаженное значение S 0 . Если вы взгляните снова на формулу простого экспоненциального сглаживания, то увидите, что следует иметь значение S 0 для вычисления первого сглаженного значения (прогноза). В зависимости от выбора параметра (в частности, если близко к 0), начальное значение сглаженного процесса может оказать существенное воздействие на прогноз для многих последующих наблюдений. Как и в других рекомендациях по применению экспоненциального сглаживания, рекомендуется брать начальное значение, дающее наилучший прогноз. С другой стороны, влияние выбора уменьшается с длиной ряда и становится некритичным при большом числе наблюдений.
экономический временный ряд статистический
Заключение
Анализ временных рядов -- совокупность математико-статистических методов анализа, предназначенных для выявления структуры временных рядов и для их прогноза. Сюда относятся, в частности, методы регрессионного анализа. Выявление структуры временного ряда необходимо для того, чтобы построить математическую модель того явления, которое является источником анализируемого временного ряда. Прогноз будущих значений временного ряда используется для эффективного принятия решений.
Временные ряды исследуются с различными целями. Метод анализа временного ряда определяется, с одной стороны, целями анализа, а с другой стороны, вероятностной природой формирования его значений.
Основными методами исследования временных рядов являются:
Ш Спектральный анализ.
Ш Корреляционный анализ
Ш Сезонная модель Бокса-Дженкинса.
Ш Прогноз экспоненциально взвешенным скользящим средним.
Литература
1. Безручко Б. П., Смирнов Д. А. Математическое моделирование и хаотические временные ряды. -- Саратов: ГосУНЦ "Колледж", 2005. -- ISBN 5-94409-045-6
2. Блехман И. И., Мышкис А. Д., Пановко Н. Г., Прикладная математика: Предмет, логика, особенности подходов. С примерами из механики: Учебное пособие. -- 3-е изд., испр. и доп. -- М.: УРСС, 2006. -- 376 с. ISBN 5-484-00163-3
3. Введение в математическое моделирование. Учебное пособие. Под ред. П. В. Трусова. -- М.: Логос, 2004. -- ISBN 5-94010-272-7
4. Горбань А. Н., Хлебопрос Р. Г., Демон Дарвина: Идея оптимальности и естественный отбор. -- М: Наука. Гл ред. физ.-мат. лит., 1988. -- 208 с. (Проблемы науки и технического прогресса) ISBN 5-02-013901-7 (Глава «Изготовление моделей»).
5. Журнал Математическое моделирование (основан в 1989 году)
6. Малков С. Ю., 2004. Математическое моделирование исторической динамики: подходы и модели // Моделирование социально-политической и экономической динамики / Ред. М. Г. Дмитриев. -- М.: РГСУ. -- с. 76-188.
7. Мышкис А. Д., Элементы теории математических моделей. -- 3-е изд., испр. -- М.: КомКнига, 2007. -- 192 с ISBN 978-5-484-00953-4
8. Самарский А. А., Михайлов А. П. Математическое моделирование. Идеи. Методы. Примеры.. -- 2-е изд., испр.. -- М.: Физматлит, 2001. -- ISBN 5-9221-0120-X
9. Советов Б. Я., Яковлев С. А., Моделирование систем: Учеб. для вузов -- 3-е изд., перераб. и доп. -- М.: Высш. шк., 2001. -- 343 с. ISBN 5-06-003860-2
Размещено на Allbest.ru
Подобные документы
Понятие и основные этапы разработки прогноза. Задачи анализа временных рядов. Оценка состояния и тенденций развития прогнозирования на основе анализа временных рядов СУ-167 ОАО "Мозырьпромстрой", практические рекомендации по его совершенствованию.
курсовая работа , добавлен 01.07.2013
Методика проведения анализа динамических рядов социально-экономических явлений. Компоненты, формирующие уровни при анализе рядов динамики. Порядок составления модели экспорта и импорта Нидерландов. Уровни автокорреляции. Корреляция рядов динамики.
курсовая работа , добавлен 13.05.2010
Методы анализа структуры временных рядов, содержащих сезонные колебания. Рассмотрение подхода методом скользящей средней и построение аддитивной (или мультипликативной) модели временного ряда. Расчет оценок сезонной компоненты в мультипликативной модели.
контрольная работа , добавлен 12.02.2015
Анализ системы показателей, характеризующих как адекватность модели, так и ее точность; определение абсолютной и средней ошибок прогноза. Основные показатели динамики экономических явлений, использование средних значений для сглаживания временных рядов.
контрольная работа , добавлен 13.08.2010
Сущность и отличительные черты статистических методов анализа: статистическое наблюдение, группировка, анализа рядов динамики, индексный, выборочный. Порядок проведения анализа рядов динамики, анализа основной тенденции развития в рядах динамики.
курсовая работа , добавлен 09.03.2010
Проведение экспериментального статистического исследования социально-экономических явлений и процессов Смоленской области на основе заданных показателей. Построение статистических графиков, рядов распределения, вариационных рядов, их обобщение и оценка.
курсовая работа , добавлен 15.03.2011
Виды временных рядов. Требования, предъявляемые к исходной информации. Описательные характеристики динамики социально-экономических явлений. Прогнозирование по методу экспоненциальных средних. Основные показатели динамики экономических показателей.
контрольная работа , добавлен 02.03.2012
Понятие и значение временного ряда в статистике, его структура и основные элементы, значение. Классификация и разновидности временных рядов, особенности сферы их применения, отличительные характеристики и порядок определения в них динамики, стадии, ряды.
контрольная работа , добавлен 13.03.2010
Определение понятия цен на продукцию и услуги; принципы их регистрации. Расчет индивидуальных и общих индексов стоимости товаров. Сущность базовых методов социально-экономических исследований - структурных средних, рядов распределения и рядов динамики.
курсовая работа , добавлен 12.05.2011
Машинное обучение и статистические методы анализа данных. Оценка точности прогнозирования. Предварительная обработка данных. Методы классификации, регрессии и анализа временных рядов. Методы ближайших соседей, опорных векторов, спрямляющего пространства.